Publications
2026
- Textual Planning with Explicit Latent TransitionsEliezer Shlomi, Ido Levy, Eilam Shapira, Michael Katz, Guy Uziel, Segev Shlomov, Nir Mashkif, Roi Reichart, and 1 more author2026
Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain’s transitions, while transfer across domain boundaries remains a bottleneck.
@misc{shlomi2026textualplanningexplicitlatent, title = {Textual Planning with Explicit Latent Transitions}, author = {Shlomi, Eliezer and Levy, Ido and Shapira, Eilam and Katz, Michael and Uziel, Guy and Shlomov, Segev and Mashkif, Nir and Reichart, Roi and Keren, Sarah}, year = {2026}, eprint = {2602.04557}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2602.04557}, } -
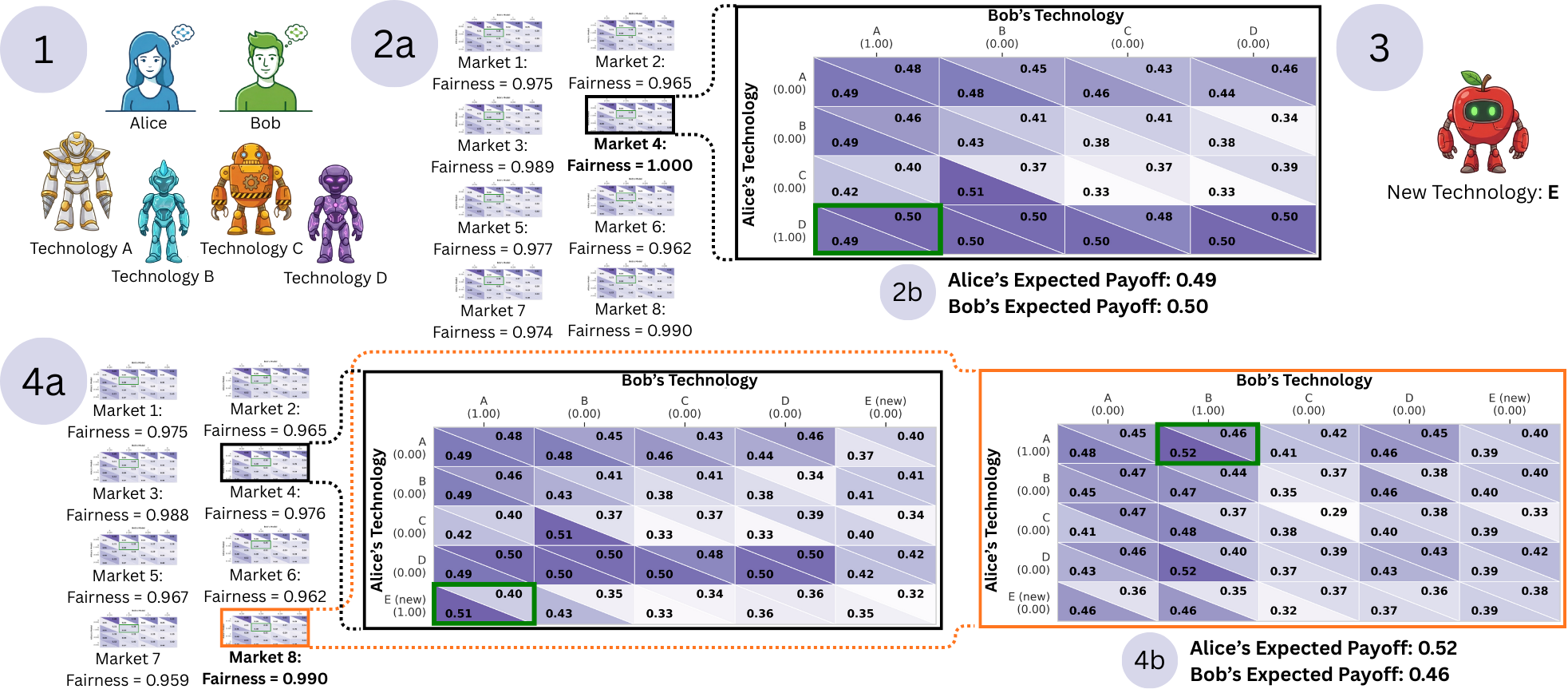 The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI AgentsEilam Shapira, Roi Reichart, and Moshe TennenholtzarXiv preprint arXiv:2601.11496, 2026
The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI AgentsEilam Shapira, Roi Reichart, and Moshe TennenholtzarXiv preprint arXiv:2601.11496, 2026The integration of AI agents into economic markets fundamentally alters the landscape of strategic interaction. We investigate the economic implications of expanding the set of available technologies in three canonical game-theoretic settings: bargaining (resource division), negotiation (asymmetric information trade), and persuasion (strategic information transmission). We find that simply increasing the choice of AI delegates can drastically shift equilibrium payoffs and regulatory outcomes, often creating incentives for regulators to proactively develop and release technologies. Conversely, we identify a strategic phenomenon termed the ”Poisoned Apple” effect: an agent may release a new technology, which neither they nor their opponent ultimately uses, solely to manipulate the regulator’s choice of market design in their favor. This strategic release improves the releaser’s welfare at the expense of their opponent and the regulator’s fairness objectives. Our findings demonstrate that static regulatory frameworks are vulnerable to manipulation via technology expansion, necessitating dynamic market designs that adapt to the evolving landscape of AI capabilities.
@article{shapira2026poisonedappleeffectstrategic, title = {The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents}, author = {Shapira, Eilam and Reichart, Roi and Tennenholtz, Moshe}, year = {2026}, eprint = {2601.11496}, archiveprefix = {arXiv}, primaryclass = {cs.GT}, journal = {arXiv preprint arXiv:2601.11496}, url = {https://arxiv.org/abs/2601.11496}, }
2025
- Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-TuningKajetan Dymkiewicz, Ivan Vulic, Helen Yannakoudakis, Eilam Shapira, Roi Reichart, and Anna KorhonenarXiv preprint arXiv:2511.13368, 2025
- From Benchmarks to Business Impact: Deploying IBM Generalist Agent in Enterprise ProductionSegev Shlomov, Alon Oved, Sami Marreed, Ido Levy, Offer Akrabi, Avi Yaeli, Łukasz Strąk, Elizabeth Koumpan, and 4 more authorsarXiv preprint arXiv:2510.23856, 2025
- NeurIPS
 TabSTAR: A Tabular Foundation Model for Tabular Data with Text FieldsAlan Arazi, Eilam Shapira, and Roi ReichartIn The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
TabSTAR: A Tabular Foundation Model for Tabular Data with Text FieldsAlan Arazi, Eilam Shapira, and Roi ReichartIn The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025While deep learning has achieved remarkable success across many domains, it has historically underperformed on tabular learning tasks, which remain dominated by gradient boosting decision trees. However, recent advancements are paving the way for Tabular Foundation Models, which can leverage real-world knowledge and generalize across diverse datasets, particularly when the data contains free-text. Although incorporating language model capabilities into tabular tasks has been explored, most existing methods utilize static, target-agnostic textual representations, limiting their effectiveness. We introduce TabSTAR: a Tabular Foundation Model with Semantically Target-Aware Representations. TabSTAR is designed to enable transfer learning on tabular data with textual features, with an architecture free of dataset-specific parameters. It unfreezes a pretrained text encoder and takes as input target tokens, which provide the model with the context needed to learn task-specific embeddings. TabSTAR achieves state-of-the-art performance for both medium- and large-sized datasets across known benchmarks of classification tasks with text features, and its pretraining phase exhibits scaling laws in the number of datasets, offering a pathway for further performance improvements.
@inproceedings{arazi2025tabstar, title = {Tab{STAR}: A Tabular Foundation Model for Tabular Data with Text Fields}, author = {Arazi, Alan and Shapira, Eilam and Reichart, Roi}, booktitle = {The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year = {2025}, url = {https://openreview.net/forum?id=FrXHdcTEzE}, } - NeurIPSFairness under CompetitionRonen Gradwohl, Eilam Shapira, and Moshe TennenholtzIn The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
Algorithmic fairness has emerged as a central issue in ML, and it has become standard practice to adjust ML algorithms so that they will satisfy fairness requirements such as Equal Opportunity. In this paper we consider the effects of adopting such fair classifiers on the overall level of ecosystem fairness. Specifically, we introduce the study of fairness with competing firms, and demonstrate the failure of fair classifiers in yielding fair ecosystems. Our results quantify the loss of fairness in systems, under a variety of conditions, based on classifiers’ correlation and the level of their data overlap. We show that even if competing classifiers are individually fair, the ecosystem’s outcome may be unfair; and that adjusting biased algorithms to improve their individual fairness may lead to an overall decline in ecosystem fairness. In addition to these theoretical results, we also provide supporting experimental evidence. Together, our model and results provide a novel and essential call for action.
@inproceedings{gradwohl2025fairness, title = {Fairness under Competition}, author = {Gradwohl, Ronen and Shapira, Eilam and Tennenholtz, Moshe}, booktitle = {The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year = {2025}, url = {https://openreview.net/forum?id=i9zoexiRFA}, } - TACL
 Human Choice Prediction in Language-based Persuasion Games: Simulation-based Off-Policy EvaluationTransactions of the Association for Computational Linguistics, Aug 2025
Human Choice Prediction in Language-based Persuasion Games: Simulation-based Off-Policy EvaluationTransactions of the Association for Computational Linguistics, Aug 2025Recent advances in Large Language Models (LLMs) have spurred interest in designing LLM-based agents for tasks that involve interaction with human and artificial agents. This paper addresses a key aspect in the design of such agents: predicting human decisions in off-policy evaluation (OPE). We focus on language-based persuasion games, where an expert aims to influence the decision-maker through verbal messages. In our OPE framework, the prediction model is trained on human interaction data collected from encounters with one set of expert agents, and its performance is evaluated on interactions with a different set of experts. Using a dedicated application, we collected a dataset of 87K decisions from humans playing a repeated decision-making game with artificial agents. To enhance off-policy performance, we propose a simulation technique involving interactions across the entire agent space and simulated decision-makers. Our learning strategy yields significant OPE gains, e.g., improving prediction accuracy in the top 15% challenging cases by 7.1%.1
@article{shapira2025human, author = {Shapira, Eilam and Madmon, Omer and Apel, Reut and Tennenholtz, Moshe and Reichart, Roi}, title = {Human Choice Prediction in Language-based Persuasion Games: Simulation-based Off-Policy Evaluation}, journal = {Transactions of the Association for Computational Linguistics}, volume = {13}, pages = {980-1006}, year = {2025}, month = aug, issn = {2307-387X}, doi = {10.1162/TACL.a.16}, url = {https://doi.org/10.1162/TACL.a.16}, eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/TACL.a.16/2549171/tacl.a.16.pdf}, } - Transition Function Prediction in AI Planning Using LLMsEliezer Shlomi, Guy Azran, Eilam Shapira, Omer Nahum, Roi Reichart, Guy Uziel, Michael Katz, Ateret Anaby Tavor, and 1 more authorIn AAAI 2025 Workshop LM4Plan, Aug 2025
@inproceedings{shlomi2025transition, title = {Transition Function Prediction in {AI} Planning Using {LLM}s}, author = {Shlomi, Eliezer and Azran, Guy and Shapira, Eilam and Nahum, Omer and Reichart, Roi and Uziel, Guy and Katz, Michael and Tavor, Ateret Anaby and Keren, Sarah}, booktitle = {AAAI 2025 Workshop LM4Plan}, year = {2025}, url = {https://openreview.net/forum?id=SPRYlWKaPj}, }
2024
-
 GLEE: A Unified Framework and Benchmark for Language-based Economic EnvironmentsEilam Shapira, Omer Madmon, Itamar Reinman, Samuel Joseph Amouyal, Roi Reichart, and Moshe TennenholtzAug 2024
GLEE: A Unified Framework and Benchmark for Language-based Economic EnvironmentsEilam Shapira, Omer Madmon, Itamar Reinman, Samuel Joseph Amouyal, Roi Reichart, and Moshe TennenholtzAug 2024Large Language Models (LLMs) show significant potential in economic and strategic interactions, where communication via natural language is often prevalent. This raises key questions: Do LLMs behave rationally? Can they mimic human behavior? Do they tend to reach an efficient and fair outcome? What is the role of natural language in the strategic interaction? How do characteristics of the economic environment influence these dynamics? These questions become crucial concerning the economic and societal implications of integrating LLMbased agents into real-world data-driven systems, such as online retail platforms and recommender systems. While the ML community has been exploring the potential of LLMs in such multi-agent setups, varying assumptions, design choices and evaluation criteria across studies make it difficult to draw robust and meaningful conclusions. To address this, we introduce a benchmark for standardizing research on two-player, sequential, language-based games. Inspired by the economic literature, we define three base families of games with consistent parameterization, degrees of freedom and economic measures to evaluate agents’ performance (self-gain), as well as the game outcome (efficiency and fairness). We develop an open-source framework for interaction simulation and analysis, and utilize it to collect a dataset of LLM vs. LLM interactions across numerous game configurations and an additional dataset of human vs. LLM interactions. Through extensive experimentation, we demonstrate how our framework and dataset can be used to: (i) compare the behavior of LLM-based agents to human players in various economic contexts; (ii) evaluate agents in both individual and collective performance measures; and (iii) quantify the effect of the economic characteristics of the environments on the behavior of agents. We believe that our framework can contribute to the growing intersection of LLMs, ML, and economics, and we encourage researchers to explore it further and build on its foundation.
@misc{shapira2024gleeunifiedframeworkbenchmark, title = {GLEE: A Unified Framework and Benchmark for Language-based Economic Environments}, author = {Shapira, Eilam and Madmon, Omer and Reinman, Itamar and Amouyal, Samuel Joseph and Reichart, Roi and Tennenholtz, Moshe}, year = {2024}, eprint = {2410.05254}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2410.05254}, } -
 Can Large Language Models Replace Economic Choice Prediction Labs? The Case of Language-based Persuasion GamesarXiv preprint arXiv:2401.17435, Aug 2024
Can Large Language Models Replace Economic Choice Prediction Labs? The Case of Language-based Persuasion GamesarXiv preprint arXiv:2401.17435, Aug 2024Human choice prediction in economic contexts is crucial for applications in marketing, finance, public policy, and more. This task, however, is often constrained by the difficulties in acquiring human choice data. With most experimental economics studies focusing on simple choice settings, the AI community has explored whether LLMs can substitute for humans in these predictions and examined more complex experimental economics settings. However, a key question remains: can LLMs generate training data for human choice prediction? We explore this in language-based persuasion games, a complex economic setting involving natural language in strategic interactions. Our experiments show that models trained on LLMgenerated data can effectively predict human behavior in these games and even outperform models trained on actual human data.
@article{shapira2024can, title = {Can Large Language Models Replace Economic Choice Prediction Labs? The Case of Language-based Persuasion Games}, author = {Shapira, Eilam and Madmon, Omer and Reichart, Roi and Tennenholtz, Moshe}, journal = {arXiv preprint arXiv:2401.17435}, year = {2024}, } - EMNLPText2Model: Text-based Model Induction for Zero-shot Image ClassificationIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
We address the challenge of building task-agnostic classifiers using only text descriptions, demonstrating a unified approach to image classification, 3D point cloud classification, and action recognition from scenes. Unlike approaches that learn a fixed representation of the output classes, we generate at inference time a model tailored to a query classification task. To generate task-based zero-shot classifiers, we train a hypernetwork that receives class descriptions and outputs a multi-class model. The hypernetwork is designed to be equivariant with respect to the set of descriptions and the classification layer, thus obeying the symmetries of the problem and improving generalization. Our approach generates non-linear classifiers, handles rich textual descriptions, and may be adapted to produce lightweight models efficient enough for on-device applications. We evaluate this approach in a series of zero-shot classification tasks, for image, point-cloud, and action recognition, using a range of text descriptions: From single words to rich descriptions. Our results demonstrate strong improvements over previous approaches, showing that zero-shot learning can be applied with little training data. Furthermore, we conduct an analysis with foundational vision and language models, demonstrating that they struggle to generalize when describing what attributes the class lacks.
@inproceedings{amosy-etal-2024-text2model, title = {{T}ext2{M}odel: Text-based Model Induction for Zero-shot Image Classification}, author = {Amosy, Ohad and Volk, Tomer and Shapira, Eilam and Ben-David, Eyal and Reichart, Roi and Chechik, Gal}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-emnlp.8}, pages = {155--172} }
Journal Articles
- TACL Human Choice Prediction in Language-based Persuasion Games: Simulation-based Off-Policy EvaluationTransactions of the Association for Computational Linguistics, Aug 2025
Recent advances in Large Language Models (LLMs) have spurred interest in designing LLM-based agents for tasks that involve interaction with human and artificial agents. This paper addresses a key aspect in the design of such agents: predicting human decisions in off-policy evaluation (OPE). We focus on language-based persuasion games, where an expert aims to influence the decision-maker through verbal messages. In our OPE framework, the prediction model is trained on human interaction data collected from encounters with one set of expert agents, and its performance is evaluated on interactions with a different set of experts. Using a dedicated application, we collected a dataset of 87K decisions from humans playing a repeated decision-making game with artificial agents. To enhance off-policy performance, we propose a simulation technique involving interactions across the entire agent space and simulated decision-makers. Our learning strategy yields significant OPE gains, e.g., improving prediction accuracy in the top 15% challenging cases by 7.1%.1
@article{shapira2025human, author = {Shapira, Eilam and Madmon, Omer and Apel, Reut and Tennenholtz, Moshe and Reichart, Roi}, title = {Human Choice Prediction in Language-based Persuasion Games: Simulation-based Off-Policy Evaluation}, journal = {Transactions of the Association for Computational Linguistics}, volume = {13}, pages = {980-1006}, year = {2025}, month = aug, issn = {2307-387X}, doi = {10.1162/TACL.a.16}, url = {https://doi.org/10.1162/TACL.a.16}, eprint = {https://direct.mit.edu/tacl/article-pdf/doi/10.1162/TACL.a.16/2549171/tacl.a.16.pdf}, }
Conference Proceedings
- NeurIPS TabSTAR: A Tabular Foundation Model for Tabular Data with Text FieldsAlan Arazi, Eilam Shapira, and Roi ReichartIn The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
While deep learning has achieved remarkable success across many domains, it has historically underperformed on tabular learning tasks, which remain dominated by gradient boosting decision trees. However, recent advancements are paving the way for Tabular Foundation Models, which can leverage real-world knowledge and generalize across diverse datasets, particularly when the data contains free-text. Although incorporating language model capabilities into tabular tasks has been explored, most existing methods utilize static, target-agnostic textual representations, limiting their effectiveness. We introduce TabSTAR: a Tabular Foundation Model with Semantically Target-Aware Representations. TabSTAR is designed to enable transfer learning on tabular data with textual features, with an architecture free of dataset-specific parameters. It unfreezes a pretrained text encoder and takes as input target tokens, which provide the model with the context needed to learn task-specific embeddings. TabSTAR achieves state-of-the-art performance for both medium- and large-sized datasets across known benchmarks of classification tasks with text features, and its pretraining phase exhibits scaling laws in the number of datasets, offering a pathway for further performance improvements.
@inproceedings{arazi2025tabstar, title = {Tab{STAR}: A Tabular Foundation Model for Tabular Data with Text Fields}, author = {Arazi, Alan and Shapira, Eilam and Reichart, Roi}, booktitle = {The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year = {2025}, url = {https://openreview.net/forum?id=FrXHdcTEzE}, } - NeurIPSFairness under CompetitionRonen Gradwohl, Eilam Shapira, and Moshe TennenholtzIn The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
Algorithmic fairness has emerged as a central issue in ML, and it has become standard practice to adjust ML algorithms so that they will satisfy fairness requirements such as Equal Opportunity. In this paper we consider the effects of adopting such fair classifiers on the overall level of ecosystem fairness. Specifically, we introduce the study of fairness with competing firms, and demonstrate the failure of fair classifiers in yielding fair ecosystems. Our results quantify the loss of fairness in systems, under a variety of conditions, based on classifiers’ correlation and the level of their data overlap. We show that even if competing classifiers are individually fair, the ecosystem’s outcome may be unfair; and that adjusting biased algorithms to improve their individual fairness may lead to an overall decline in ecosystem fairness. In addition to these theoretical results, we also provide supporting experimental evidence. Together, our model and results provide a novel and essential call for action.
@inproceedings{gradwohl2025fairness, title = {Fairness under Competition}, author = {Gradwohl, Ronen and Shapira, Eilam and Tennenholtz, Moshe}, booktitle = {The Thirty-ninth Annual Conference on Neural Information Processing Systems}, year = {2025}, url = {https://openreview.net/forum?id=i9zoexiRFA}, } - EMNLPText2Model: Text-based Model Induction for Zero-shot Image ClassificationIn Findings of the Association for Computational Linguistics: EMNLP 2024, Nov 2024
We address the challenge of building task-agnostic classifiers using only text descriptions, demonstrating a unified approach to image classification, 3D point cloud classification, and action recognition from scenes. Unlike approaches that learn a fixed representation of the output classes, we generate at inference time a model tailored to a query classification task. To generate task-based zero-shot classifiers, we train a hypernetwork that receives class descriptions and outputs a multi-class model. The hypernetwork is designed to be equivariant with respect to the set of descriptions and the classification layer, thus obeying the symmetries of the problem and improving generalization. Our approach generates non-linear classifiers, handles rich textual descriptions, and may be adapted to produce lightweight models efficient enough for on-device applications. We evaluate this approach in a series of zero-shot classification tasks, for image, point-cloud, and action recognition, using a range of text descriptions: From single words to rich descriptions. Our results demonstrate strong improvements over previous approaches, showing that zero-shot learning can be applied with little training data. Furthermore, we conduct an analysis with foundational vision and language models, demonstrating that they struggle to generalize when describing what attributes the class lacks.
@inproceedings{amosy-etal-2024-text2model, title = {{T}ext2{M}odel: Text-based Model Induction for Zero-shot Image Classification}, author = {Amosy, Ohad and Volk, Tomer and Shapira, Eilam and Ben-David, Eyal and Reichart, Roi and Chechik, Gal}, editor = {Al-Onaizan, Yaser and Bansal, Mohit and Chen, Yun-Nung}, booktitle = {Findings of the Association for Computational Linguistics: EMNLP 2024}, month = nov, year = {2024}, address = {Miami, Florida, USA}, publisher = {Association for Computational Linguistics}, url = {https://aclanthology.org/2024.findings-emnlp.8}, pages = {155--172} }
Workshops
- Transition Function Prediction in AI Planning Using LLMsEliezer Shlomi, Guy Azran, Eilam Shapira, Omer Nahum, Roi Reichart, Guy Uziel, Michael Katz, Ateret Anaby Tavor, and 1 more authorIn AAAI 2025 Workshop LM4Plan, 2025
@inproceedings{shlomi2025transition, title = {Transition Function Prediction in {AI} Planning Using {LLM}s}, author = {Shlomi, Eliezer and Azran, Guy and Shapira, Eilam and Nahum, Omer and Reichart, Roi and Uziel, Guy and Katz, Michael and Tavor, Ateret Anaby and Keren, Sarah}, booktitle = {AAAI 2025 Workshop LM4Plan}, year = {2025}, url = {https://openreview.net/forum?id=SPRYlWKaPj}, }
Preprints
- The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI AgentsEilam Shapira, Roi Reichart, and Moshe TennenholtzarXiv preprint arXiv:2601.11496, 2026
The integration of AI agents into economic markets fundamentally alters the landscape of strategic interaction. We investigate the economic implications of expanding the set of available technologies in three canonical game-theoretic settings: bargaining (resource division), negotiation (asymmetric information trade), and persuasion (strategic information transmission). We find that simply increasing the choice of AI delegates can drastically shift equilibrium payoffs and regulatory outcomes, often creating incentives for regulators to proactively develop and release technologies. Conversely, we identify a strategic phenomenon termed the ”Poisoned Apple” effect: an agent may release a new technology, which neither they nor their opponent ultimately uses, solely to manipulate the regulator’s choice of market design in their favor. This strategic release improves the releaser’s welfare at the expense of their opponent and the regulator’s fairness objectives. Our findings demonstrate that static regulatory frameworks are vulnerable to manipulation via technology expansion, necessitating dynamic market designs that adapt to the evolving landscape of AI capabilities.
@article{shapira2026poisonedappleeffectstrategic, title = {The Poisoned Apple Effect: Strategic Manipulation of Mediated Markets via Technology Expansion of AI Agents}, author = {Shapira, Eilam and Reichart, Roi and Tennenholtz, Moshe}, year = {2026}, eprint = {2601.11496}, archiveprefix = {arXiv}, primaryclass = {cs.GT}, journal = {arXiv preprint arXiv:2601.11496}, url = {https://arxiv.org/abs/2601.11496}, } - Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-TuningKajetan Dymkiewicz, Ivan Vulic, Helen Yannakoudakis, Eilam Shapira, Roi Reichart, and Anna KorhonenarXiv preprint arXiv:2511.13368, 2025
- From Benchmarks to Business Impact: Deploying IBM Generalist Agent in Enterprise ProductionSegev Shlomov, Alon Oved, Sami Marreed, Ido Levy, Offer Akrabi, Avi Yaeli, Łukasz Strąk, Elizabeth Koumpan, and 4 more authorsarXiv preprint arXiv:2510.23856, 2025
- Can Large Language Models Replace Economic Choice Prediction Labs? The Case of Language-based Persuasion GamesarXiv preprint arXiv:2401.17435, 2024
Human choice prediction in economic contexts is crucial for applications in marketing, finance, public policy, and more. This task, however, is often constrained by the difficulties in acquiring human choice data. With most experimental economics studies focusing on simple choice settings, the AI community has explored whether LLMs can substitute for humans in these predictions and examined more complex experimental economics settings. However, a key question remains: can LLMs generate training data for human choice prediction? We explore this in language-based persuasion games, a complex economic setting involving natural language in strategic interactions. Our experiments show that models trained on LLMgenerated data can effectively predict human behavior in these games and even outperform models trained on actual human data.
@article{shapira2024can, title = {Can Large Language Models Replace Economic Choice Prediction Labs? The Case of Language-based Persuasion Games}, author = {Shapira, Eilam and Madmon, Omer and Reichart, Roi and Tennenholtz, Moshe}, journal = {arXiv preprint arXiv:2401.17435}, year = {2024}, }
- Textual Planning with Explicit Latent TransitionsEliezer Shlomi, Ido Levy, Eilam Shapira, Michael Katz, Guy Uziel, Segev Shlomov, Nir Mashkif, Roi Reichart, and 1 more author2026
Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain’s transitions, while transfer across domain boundaries remains a bottleneck.
@misc{shlomi2026textualplanningexplicitlatent, title = {Textual Planning with Explicit Latent Transitions}, author = {Shlomi, Eliezer and Levy, Ido and Shapira, Eilam and Katz, Michael and Uziel, Guy and Shlomov, Segev and Mashkif, Nir and Reichart, Roi and Keren, Sarah}, year = {2026}, eprint = {2602.04557}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2602.04557}, } - GLEE: A Unified Framework and Benchmark for Language-based Economic EnvironmentsEilam Shapira, Omer Madmon, Itamar Reinman, Samuel Joseph Amouyal, Roi Reichart, and Moshe Tennenholtz2024
Large Language Models (LLMs) show significant potential in economic and strategic interactions, where communication via natural language is often prevalent. This raises key questions: Do LLMs behave rationally? Can they mimic human behavior? Do they tend to reach an efficient and fair outcome? What is the role of natural language in the strategic interaction? How do characteristics of the economic environment influence these dynamics? These questions become crucial concerning the economic and societal implications of integrating LLMbased agents into real-world data-driven systems, such as online retail platforms and recommender systems. While the ML community has been exploring the potential of LLMs in such multi-agent setups, varying assumptions, design choices and evaluation criteria across studies make it difficult to draw robust and meaningful conclusions. To address this, we introduce a benchmark for standardizing research on two-player, sequential, language-based games. Inspired by the economic literature, we define three base families of games with consistent parameterization, degrees of freedom and economic measures to evaluate agents’ performance (self-gain), as well as the game outcome (efficiency and fairness). We develop an open-source framework for interaction simulation and analysis, and utilize it to collect a dataset of LLM vs. LLM interactions across numerous game configurations and an additional dataset of human vs. LLM interactions. Through extensive experimentation, we demonstrate how our framework and dataset can be used to: (i) compare the behavior of LLM-based agents to human players in various economic contexts; (ii) evaluate agents in both individual and collective performance measures; and (iii) quantify the effect of the economic characteristics of the environments on the behavior of agents. We believe that our framework can contribute to the growing intersection of LLMs, ML, and economics, and we encourage researchers to explore it further and build on its foundation.
@misc{shapira2024gleeunifiedframeworkbenchmark, title = {GLEE: A Unified Framework and Benchmark for Language-based Economic Environments}, author = {Shapira, Eilam and Madmon, Omer and Reinman, Itamar and Amouyal, Samuel Joseph and Reichart, Roi and Tennenholtz, Moshe}, year = {2024}, eprint = {2410.05254}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, url = {https://arxiv.org/abs/2410.05254}, }