Human Choice Prediction
Human choice prediction in a language-based persuasion game using gut feelings and LLM-generated data.
This page introduces my main research focus during the first two years of my PhD: predicting human decisions in a language-based persuasion game.
The Setup
In a pair of papers (missing reference), written with my co-authors Omer Madmon, Reut Apel, Moshe Tennenholtz, and Roi Reichart, we designed a novel language-based persuasion game between two players: a human decision-maker and a bot playing the sender.
In each round, a hotel is drawn and presented to the bot, who knows whether it’s good or bad. The bot then chooses one of seven textual reviews to send to the human. The human, playing the role of a traveler, must decide whether to visit the hotel or not, based solely on the review and their prior experience with the bot.

The Dataset
To study this interaction at scale, we developed a mobile app in which human participants played this game against multiple bot agents. The result is a dataset of 87,204 decisions from 245 unique human players, each of whom played against six expert bots until they managed to “beat” each one.



We divided the participants into a training set (210 players) and a test set (35 players), with each group playing against a different set of bots. To our knowledge, this is the largest dataset of human decisions in a language-based game-theoretic setting. The dataset is presented in our first paper (missing reference) and is available on Kaggle at this like.
Predicting Human Decisions: The Off-Policy Setup
Both papers focus on predicting the human player’s next move, given the hotel review and their full interaction history up to that point.
In the first paper (missing reference) we tackled the off-policy evaluation setting: predicting human decisions when interacting with previously unseen bot strategies, i.e., test-set agents that differ from those seen during training.
While this dataset is rich, modeling human behavior under unseen conditions remains difficult due to limited coverage of the vast space of possible interactions. To tackle this we proposed a simulation-based approach: we generate synthetic but realistic human decisions using interpretable heuristics. This approach enables us to (1) Augment training with additional trajectories; (2) Introduce behavioral diversity; And most importantly: (3) generalize to unseen bots.
The Simulation Framework
When we considered simple heuristics that humans may exhibit in our game, we roughly categorized them into three main heuristics. In the first one, “Language-based”, the actions taken are solely based on reading the presented review and analyzing its sentiment: choose to go to the hotel if the review is positive, and skip the hotel if the review isn’t good. The second heuristic, which we called “Truthful”, is based on the trust level that the human decision maker has in the travel agent: Go to the hotel only if in the last few rounds the travel agent sent reviews that demonstrate the real quality of the hotel and the current review is positive. In the third heuristic, “Random”, the decision maker makes an arbitrary choice. Using these three heuristics, we created simulated decision-makers. For each decision-maker, we drew a probability vector called the “nature vector,” which describes the probability of this decision-maker playing each of the three basic behaviors. Each round, we draw one of the basic behaviors using this vector and perform the decision-maker action based on it. In that way, we can generate as much data as we want.
The Secret Sauce: Gut Feeling
In addition to the main basic behavior detailed above, we presented a fourth heuristic, “Oracle”, in which the decision maker simply makes the right decision for themselves: go to good hotels and skip the bad ones. When meeting a new agent, the decision maker has no gut feeling about how to react to the agent’s review, so the probability of playing “Oracle” is defined as 0. As the interaction progresses, and more rounds are played, the decision maker develops his gut feeling, and the probability of playing “Oracle” increases.

Key Results
Simulation improved prediction accuracy, especially on hard-to-predict examples. The best performance came from hybrid training (real + simulated data), with LSTM improving by 7.1% on hard examples. Crucially, the Oracle heuristic, which models humans developing trust over time, was essential. Without it, simulation offered little benefit. Combining Oracle with realistic heuristics enabled strong generalization across diverse bot strategies.
Can LLMs Replace Human Data?
In our second paper (Shapira et al., 2024), we took a bold step forward: What if we could predict human decisions without using any human data at training time?
Collecting real human decisions is expensive, time-consuming, and riddled with privacy and logistical challenges. To tackle this, we explored whether Large Language Models (LLMs) can act as human proxies, simulating realistic decision trajectories in our persuasion game.
We replaced real participants with LLMs, instructing them to act as decision-makers using the same setup as our human experiment. Crucially, we diversified LLM behaviors using personas: prompt variations that encourage different types of reasoning (e.g., someone who values cleanliness or location, or is generally optimistic).
Key Insight: LLMs Can Predict Humans
We trained prediction models using only LLM-generated data and evaluated them on our real human test set. Astonishingly, once enough synthetic data was generated, models trained on LLM decisions outperformed models trained on real human data.
Even better, combining real and LLM-generated data yielded the best of both worlds: strong accuracy and improved calibration, a key metric when prediction confidence matters.
References
2024
-
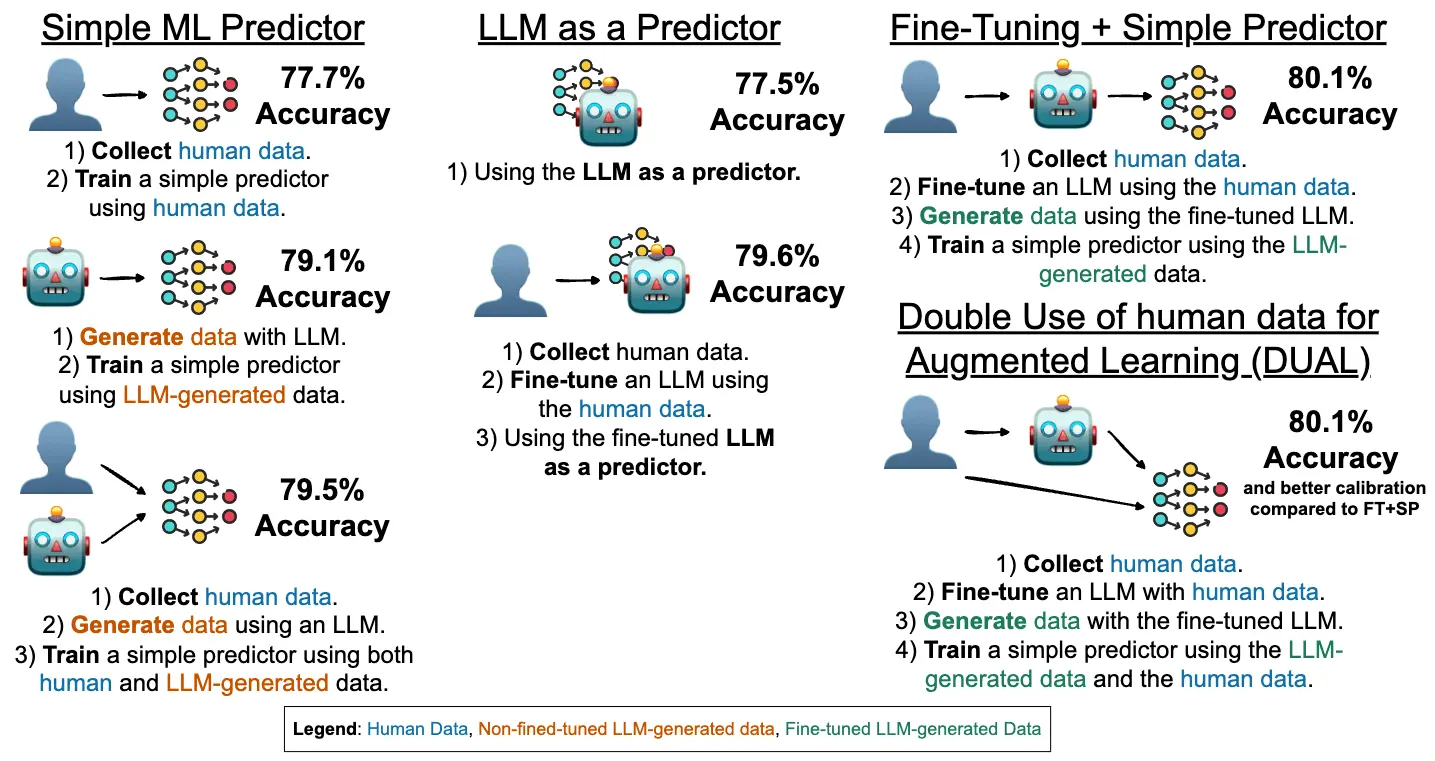
Results for the prediction task introduced in the paper, comparing alternative ways to use data from the 110 human players and from the LLM-generated players.